发布时间: 2021-11-18
作者:沈维波 专利代理师
一、引言
近年来,随着人工智能技术的发展,机器学习在零售、医疗、金融、自动驾驶、新闻事件识别以及音乐自动生成等领域均有着广泛的应用。然而,很多机器学习模型类似于“黑盒”,输入数据后即可得到输出结果,使得大部分涉及机器学习模型的案件都存在极大的相似性。
因此,如何在具体实施例中,对机器学习模型对输入数据的处理过程进行详细的描述,进而使得该方案区别于其他方案最终达到授权的目的,是撰写机器学习类案件的具体实施例的重点。
二、关于机器学习类案件的实施例的撰写案例
在对机器学习类案件的具体撰写过程中,可以采用如下方式进行:首先,介绍模型的具体结构;其次,介绍模型的具体运算原理;最后,给出具体的实际执行示例。或者,在对模型的结构进行描述和/或模型的具体应用过程中,可以结合技术方案所要解决的技术问题进行重点描述,使之区别于现有技术,最终达到授权的目的。
接下来,通过两个案例进行具体说明:
案例1:以Bert模型为例,对Bert模型如何实现文本抽取的具体处理过程进行说明。
首先,该模型可以包括多个Transformer模型、权重融合层以及全连接层,其具体的结构示例图可以参考如下图1所示。

图1
其次,该模型的实现原理为:在数据输入端,首先将输入的数据编码成一个字嵌入矩阵以及位置嵌入矩阵;然后,将字嵌入矩阵以及位置嵌入矩阵两个向量相加作为总的输入嵌入表示,再将总的输入嵌入表示通过一个N层的Transformer网络得到文本语义表示向量以及每个Transformer的重要程度;紧接着,通过权重融合层对所有Transformer层的重要程度进行融合得到编码向量;最后,利用全连接层对编码向量进行计算,即可得到最终的输出结果。
最后,在具体的使用过程中,可以通过如下方式实现对文本的抽取:首先,将输入的句子(例如可以是:北京时间3月27日晚,英国首相鲍里斯约翰逊确诊感染了新冠肺炎)
其次,将字嵌入矩阵以及位置嵌入矩阵两个向量相加作为总的输入嵌入表示
其中,
同时,为了有效利用Bert中每一层的信息,可以学习每个Transformer的重要程度
其中,
然后,将BERT中所有的Transformer的结果进行拼接得到融合表示,具体可以如下公式(5)所示:
进一步的,对公式(4)得到的权重以及公式(5)得到的融合表示进行加权融合可以得到最终的融合语义表示
最后,然后将BERT输出的编码向量通过全连接层,最终输出序列每个位置上的值即为实体起止位置的置信度。其中,置信度的具体计算过程可以如下公式(7)以及公式(8)所示:
其中,
案例2:以包括长短期记忆网络的模型为例,对时间序列数据的具体处理过程进行举例说明。
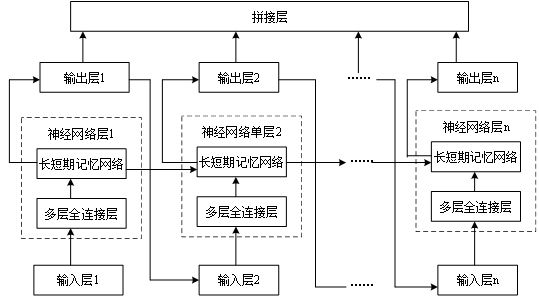
首先,该模型可以包括多个输入层、由多个全连接层以及长短期记忆网络组成的神经网络层、多个输出层以及拼接层,具体可以如下图2所示。其中,在该模型中,每一个神经网络层分别连接一个输入层以及一个输出层,各输出层均与拼接层连接,并且,第一个神经网络层的输出是第二个网络神经层的输入的一部分,第二神经网络层的输出,是第三个神经网络层的输入的一部分,依次类推;同时,在其他神经网络层中,上一个神经网络层的长短期记忆网络以及与其相邻的神经网络层的长短期记忆网络是相连的,这样可以保证最终得到的输出数据的精确度。
图2
其次,以输入数据为音乐数据为例,对上述模型的具体计算原理进行解释以及说明。首先,输入数据包括:音乐生成参数、随机数向量(目的在于为生成的音乐带来变化,每一个神经网络层对应一个不同的随机向量)、时间特征(即当前帧在全曲中的时间位置信息);其次,经过多层全连接对音乐生成参数、随机数向量以及时间特征进行特征整理得到输入特征向量,并通过长短期记忆网络层对输入特征向量进行时序关联和推演的网络计算,通过输出层输出多个子数据;最后,通过拼接层对子数据进行拼接即可得到输出数据,该输出数据可以是音频或者频谱图。
三、结合上述案例,为专利代理师在撰写机器学习类案件的具体实施例的过程中,提供如下建议:
首先,在与发明人沟通的过程中,尽可能详细的让发明人对本申请中所涉及到的模型的具体结构、模型的实现原理以及该模型如何应用到本申请中并解决相关的技术问题,进行解释以及说明。
其次,若发明人无法提供,可以结合代理师自身在执业过程中所累积的经验以及现有技术所提供的相关文献,对模型的具体结构、模型的计算原理以及模型的具体应用进行合乎逻辑的推断以及扩充,并请求发明人对推断以及扩充部分的准确性进行确认。
最后,在具体的执业过程中,可以实时的对涉及到各种类别不同的机器学习模型进行记录,以达到融会贯通、积少成多的目的。
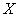 编码成一个字嵌入矩阵
编码成一个字嵌入矩阵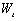 以及位置嵌入矩阵
以及位置嵌入矩阵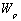 ;其中,
;其中,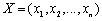 。
。
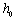 ,再将输入的向量表示
,再将输入的向量表示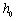 通过一个N层的Transformer网络得到文本语义表示向量
通过一个N层的Transformer网络得到文本语义表示向量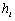 ,具体可以如下公式(1)以及公式(2)所示:
,具体可以如下公式(1)以及公式(2)所示:
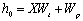 ; 公式(1)
; 公式(1)
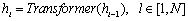 ; 公式(2)
; 公式(2)
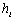 为隐藏层向量,即第
为隐藏层向量,即第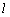 层Transformer网络的输出。
层Transformer网络的输出。
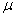 ,然后将所有Transformer层的结果加权叠加得到最终的语义表征,具体可以如下公式(3)所示:
,然后将所有Transformer层的结果加权叠加得到最终的语义表征,具体可以如下公式(3)所示:
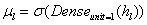 ; 公式(3)
; 公式(3)
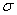 为ReLu激活函数;其次,通过权重融合层将每一层的权重进行拼接,并用softmax函数进行归一化得到一个1*L的权重向量
为ReLu激活函数;其次,通过权重融合层将每一层的权重进行拼接,并用softmax函数进行归一化得到一个1*L的权重向量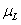 ,具体可以如下公式(4)所示:
,具体可以如下公式(4)所示:
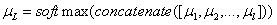 ; 公式(4)
; 公式(4)
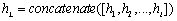 ; 公式(5)
; 公式(5)
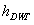 ,也即最终的编码向量,具体可以如下公式(6)所示:
,也即最终的编码向量,具体可以如下公式(6)所示:
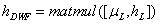 ; 公式(6)
; 公式(6)
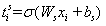 ; 公式(7)
; 公式(7)
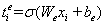 ; 公式(8)
; 公式(8)
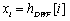 ,也即原始文本数据第i个字符经过BERT编码后输出的编码向量,
,也即原始文本数据第i个字符经过BERT编码后输出的编码向量,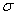 为sigmoid激活函数,
为sigmoid激活函数,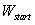 以及
以及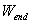 为预设的可训练的权重(参数),
为预设的可训练的权重(参数),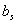 以及
以及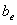 为相应的偏置项(参数),
为相应的偏置项(参数),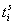 以及
以及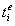 分别为原始文本数据第i个字符为触发词的开始位置以及终止位置的概率,当概率大于预设阈值(0.45)时,则相应位置会标志为1,否则会标志为0;最终得到的文本抽取结果例如可以是:感染。
分别为原始文本数据第i个字符为触发词的开始位置以及终止位置的概率,当概率大于预设阈值(0.45)时,则相应位置会标志为1,否则会标志为0;最终得到的文本抽取结果例如可以是:感染。